
VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
Published in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 (CVPR 2023)

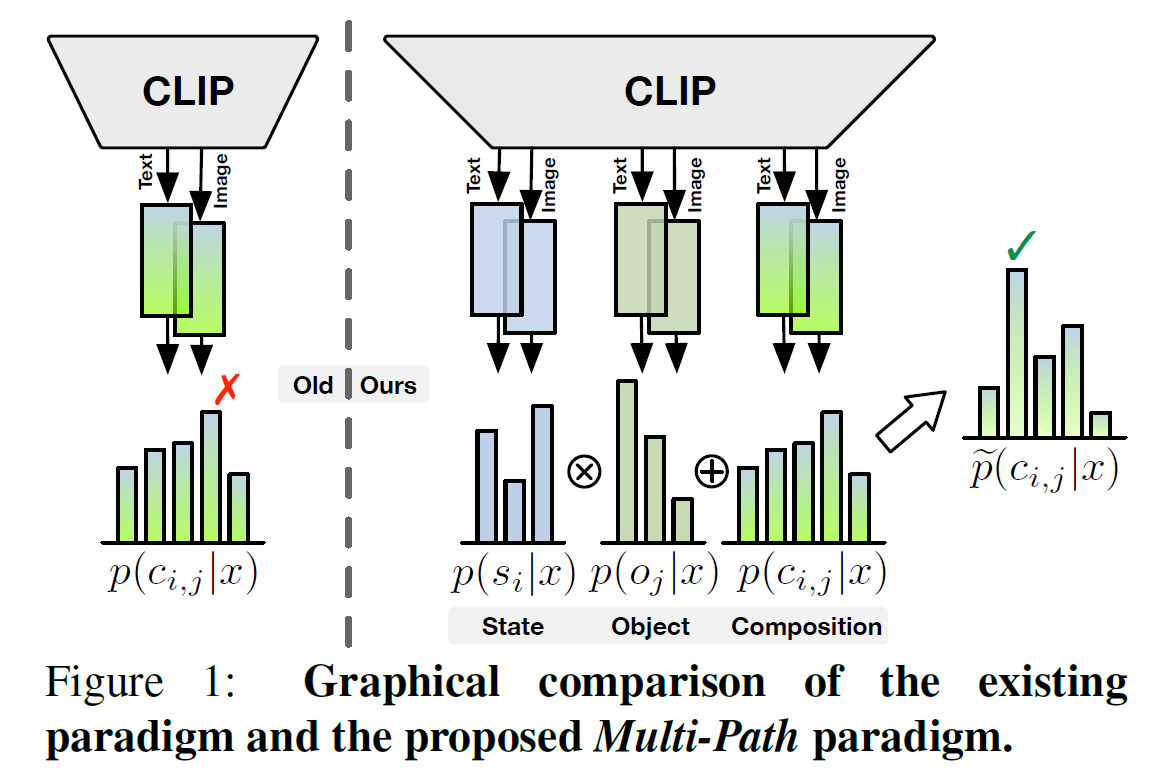
In this work, we propose the VoP: Text-Video Co-operative Prompt Tuning for efficient tuning on the text-video retrieval task. The proposed VoP is an end-to-end framework with both video & text prompts introducing, which can be regarded as a powerful baseline with only 0.1% trainable parameters. Further, based on the spatio-temporal characteristics of videos, we develop three novel video prompt mechanisms to improve the performance with different scales of trainable parameters. The basic idea of the VoP enhancement is to model the frame position, frame context, and layer function with specific trainable prompts, respectively. Extensive experiments show that compared to full finetuning, the enhanced VoP achieves a 1.4% average R@1 gain across five text-video retrieval benchmarks with 6× less parameter overhead.

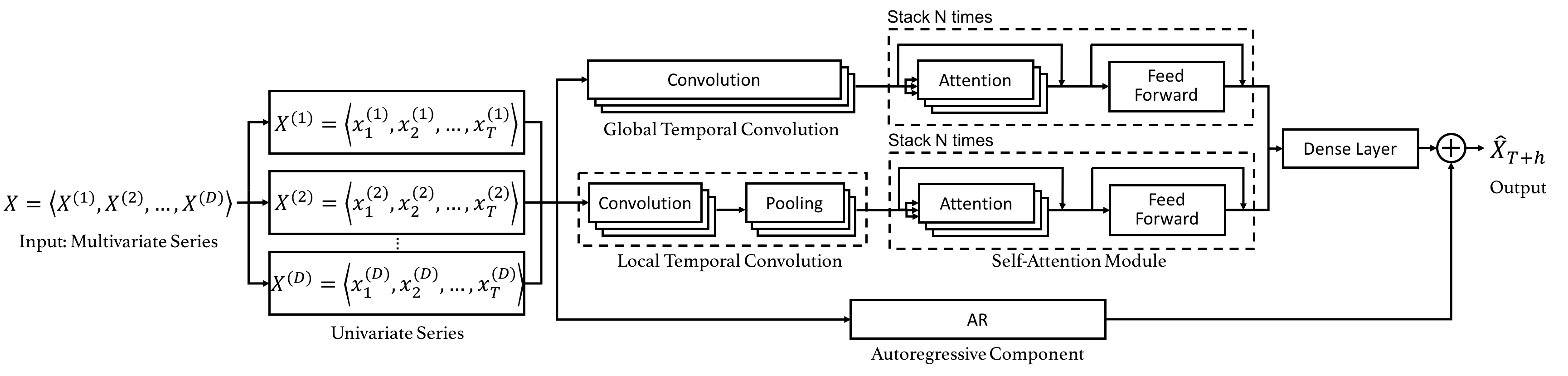 In this paper, we propose a dual self-attention network (DSANet) for multivariate time series forecasting, especially for dynamic-period or nonperiodic series. DSANet completely dispenses with recurrence and utilizes two parallel convolutional components, called global temporal convolution and local temporal convolution, to capture complex mixtures of global and local temporal patterns. Moreover, DSANet employs a self-attention module to model dependencies between multiple series. To further improve the robustness, DSANet also integrates a traditional autoregressive linear model in parallel to the non-linear neural network. Experiments on real-world multivariate time series data show that the proposed model is effective and outperforms baselines.
In this paper, we propose a dual self-attention network (DSANet) for multivariate time series forecasting, especially for dynamic-period or nonperiodic series. DSANet completely dispenses with recurrence and utilizes two parallel convolutional components, called global temporal convolution and local temporal convolution, to capture complex mixtures of global and local temporal patterns. Moreover, DSANet employs a self-attention module to model dependencies between multiple series. To further improve the robustness, DSANet also integrates a traditional autoregressive linear model in parallel to the non-linear neural network. Experiments on real-world multivariate time series data show that the proposed model is effective and outperforms baselines.